中国信通院闫树:大规模应用的前夜 让市场接受隐私计算的技术理念至关重要
11月3日,“第十六届21世纪亚洲金融年会”金融科技主题论坛在北京举办。在以“数据隐私保护与风控迭代”为主题的圆桌讨论环节上,中国信通院云大所大数据与区块链部副主任闫树表示,隐私计算正在慢慢地从技术阶段向应用阶段过渡,正处于“大规模应用的前夜”。对于隐私计算当前面临的困境,实际上是很多种解决的方式,最重要是如何让市场认知和接受隐私计算的技术理念。
何为隐私计算?
据闫树介绍,隐私计算是隐私保护计算的简称,可将其定义概括为——在不传递原始数据或保护原始数据的前提下,实现数据的分析、计算、应用的一类技术集合或体系。目前隐私计算有很多的技术路线,常见的有密码学、可信硬件、联邦学习等。
密码学方式。闫树介绍道,“以前对数据进行共同计算时,企业双方需要交换数据或者把数据交给第三方,这样其实是会暴露数据。如果是用密码学的方式,企业就可以把数据加密后再给出去。另一方对加密数据进行分析计算,将结果反馈回去。这就是在没有得到原始数据的情况下,通过加密算法来进行隐私计算的一类方式。”
可信硬件方式。闫树解释说,通过可信硬件可以构造一个安全、可信的硬件环境,我们认为把数据放在可信环境中安全性是有保证的。
联邦学习方式。闫树表示,国内外衍生出了联邦学习、共享学习、知识联邦、联邦智能等一系列旨在解决多方数据联合机器学习的“联邦学习类”技术。联邦学习的本质是分布式的机器学习,在保证数据隐私安全的基础上,实现共同建模,提升模型的效果。联邦学习的目标是在不聚合参与方原始数据的前提下,实现保护终端数据隐私的联合建模。实际上,这就是“数据不动价值动”、“可用不可见”的过程。
在闫树看来,隐私计算正处于“大规模应用的前夜”。目前,隐私计算正在慢慢地从技术阶段向应用阶段过渡。越来越多的隐私计算招标项目,尤其是在今年下半年出现了迅猛增长,这在一定程度上代表了技术发展的阶段。
与多种技术融合以补短板
任何一项技术大规模应用的过程都不是一蹴而就的,隐私计算亦是如此。闫树表示,目前各家企业对隐私计算的应用更多的是属于测试性质,或者是在小系统范围内使用,还没到大规模扩展到全集团、全行业、甚至是跨行业的应用范围,此类案例非常之少。他认为,之所以如此,主要是因为安全性、性能、合规等方面的问题。
首先是安全性。闫树解释道,数据是机构最核心、最机密的资源,安全性不能出现任何问题。同时,隐私计算的技术门槛比较高。一方面是难以向合规部门解释,另一方面我们对隐私计算技术的信任暂时还没有到全面铺开使用的程度,这个问题需要利用一些手段去解决。
其次是性能。闫树表示,作为学术研究项目,多方安全计算早在1982年就被提出来了。为什么没有得到广泛应用?因为从当时的算力或运算成本来看是不可接受的。但是,随着近年来各种算法和协议的优化、算力算法的提升,很大程度上已经具备的一定的可行性。他举例称,“信通院对联合统计、联合建模等技术在各种场景应用的性能测试结果显示,目前大部分情况是小时级、分钟级的具备了一定的可用性。然而,一旦数据量增加、交互方变多、数据结构变复杂,性能下降十分明显。这就需要我们从技术角度不断提升技能。”
此外,还有合规问题。闫树说,隐私计算本身可解决的问题不是特别广。它只是提供了不交换原始数据的解决路径,这只是数据流通全过程中的一个环节,流通前和流通后的问题是无法用隐私计算解决的。比如,原始数据自身的合规性,隐私计算后的结果等。“这就需要隐私计算与更多的技术协同。”他进一步表示,一方面是隐私计算内部的TEE(多方安全计算)、MPC(可信执行环境)、FL(联邦学习)等技术融合;另一方面是与区块链、人工智能等更多技术的融合,以弥补各自的短板。
在闫树看来,解决隐私计算面临的上述问题其实很多种方式,最重要是如何让市场认知和接受隐私计算的技术理念。
(文章来源:21世纪经济报道)
-
 前三季度完成交通固定资产投资25632亿元 同比增长2% 记者今天从交通运输部获悉,前三季度,交通运输经济运行总体平稳,交通投资、货运量、港口货物吞吐量两年平均增速均在6%左右,其中三季度受
前三季度完成交通固定资产投资25632亿元 同比增长2% 记者今天从交通运输部获悉,前三季度,交通运输经济运行总体平稳,交通投资、货运量、港口货物吞吐量两年平均增速均在6%左右,其中三季度受 -
 1-9月份第一产业投资10395亿元 同比增长14.0% 据国家统计局官网消息,1-9月份,全国固定资产投资(不含农户)397827亿元,同比增长7 3%;比2019年1-9月份增长7 7%,两年平均增长3 8%。其中
1-9月份第一产业投资10395亿元 同比增长14.0% 据国家统计局官网消息,1-9月份,全国固定资产投资(不含农户)397827亿元,同比增长7 3%;比2019年1-9月份增长7 7%,两年平均增长3 8%。其中 -
 1-8月河南省货物贸易保持高速增长 商务运行稳中有进 据河南省商务厅官网消息,2021年1-8月,全省货物贸易保持高速增长,招商引资保持增长态势,消费品市场恢复态势放缓,对外投资大幅增长,商
1-8月河南省货物贸易保持高速增长 商务运行稳中有进 据河南省商务厅官网消息,2021年1-8月,全省货物贸易保持高速增长,招商引资保持增长态势,消费品市场恢复态势放缓,对外投资大幅增长,商 -
 医药板块投资性价比显现 基金公司密集调研医药上市公司 12月14日,资本邦了解到,随着年内的持续调整,此前一直处于高估值的医药板块投资性价比显现,因此基金公司对相关主题基金的布局速度加快。
医药板块投资性价比显现 基金公司密集调研医药上市公司 12月14日,资本邦了解到,随着年内的持续调整,此前一直处于高估值的医药板块投资性价比显现,因此基金公司对相关主题基金的布局速度加快。 -
 稳增长预期确认 中信证券:跨年蓝筹行情预计将延续数月 12月13日,资本邦了解到,上周(12月6日—12月10日),A股在央行宣布全面降准0 5个百分点后,迎来震荡上行,上证指数周涨幅1 63%,深证成指全
稳增长预期确认 中信证券:跨年蓝筹行情预计将延续数月 12月13日,资本邦了解到,上周(12月6日—12月10日),A股在央行宣布全面降准0 5个百分点后,迎来震荡上行,上证指数周涨幅1 63%,深证成指全 -
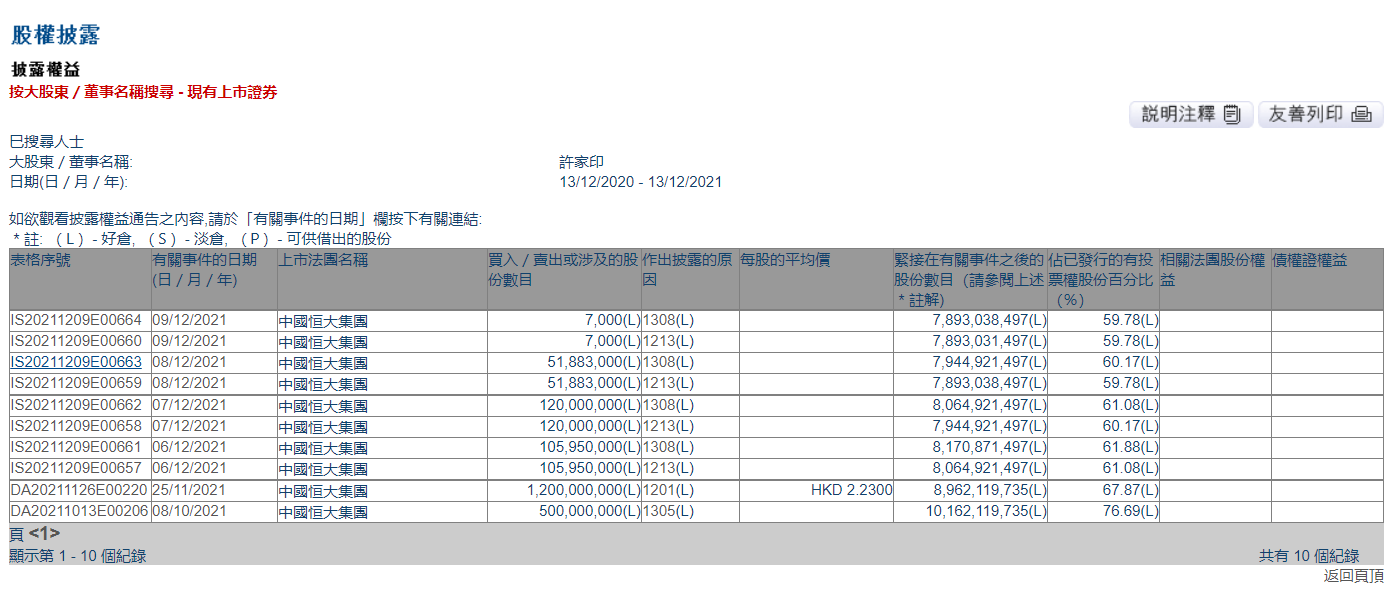 许家印在中国恒大持股比例从61.88%下降至59.78% 12月13日,资本邦了解到,港交所文件显示,依据强制处置事项,12月6日、12月7日、12月8日、12月9日,许家印持续被强制卖出中国恒大1 06亿股
许家印在中国恒大持股比例从61.88%下降至59.78% 12月13日,资本邦了解到,港交所文件显示,依据强制处置事项,12月6日、12月7日、12月8日、12月9日,许家印持续被强制卖出中国恒大1 06亿股
-
国联股份:全国营销体系建设项目是建立健全一个基本满足多多电商平台属地服务的全... 每经AI快讯,有投资者在投资者互动平台提问:潘总您好,IPO募集的资金中有7940万元用于全国营销体系建设项目,麻烦潘总介绍下这个项目。目前进
-
奇安信吴云坤:零信任是数据安全的必然选择和创新方向 “数据安全是数字化时代关基保护的核心和关键。”12月16日,在由中国计算机学会计算机安全专委会数据安全工作组举办的“零信任分论坛”...
-
中矿资源:年内可完成3000吨/年扩建至6000吨/年的氟化锂技改项目 【中矿资源:年内可完成3000吨 年扩建至6000吨 年的氟化锂技改项目】中矿资源(002738)12月17日在互动平台表示,根据目前公司工作进展情况来看
-
恒生科指又创新低!港股究竟有多“便宜”?券商:明年配置这些板块! 恒生科指又创新低!港股究竟有多“便宜”?券商:明年配置这些板块!新经济是港股胜负手。
-
广东省政府副秘书长、省政数局局长杨鹏飞到茂名调研“办事不出村”改革工作 日前,广东省政府副秘书长、省政数局局长杨鹏飞带队到茂名调研,深入茂名高州云潭镇读岗村了解“办事不出村”改革工作情况。杨鹏飞一行...
-
大鹏街道蝶变记②丨一轴两湾多点集中发力 大鹏街道推动经济高质量发展 在加快“生态立区经济强区”建设,全面开启大鹏高质量发展的征途上,大鹏办事处全面贯彻新发展理念,硬环境建设,软实力提升,锚定目标...
-
“网红神盘”不香了?深圳豪宅新盘大降温 此前曾遭疯抢 严控下购房者变理性 【“网红神盘”不香了?深圳豪宅新盘大降温此前曾遭疯抢严控下购房者变理性】隆冬时节,深圳的新房市场也寒意阵阵。备受市场瞩目的深圳...
-
菲达环保三度谋划资产重组背后:内幕交易、信披数据“打架”、疑借收购提升业绩 时隔近五个月,菲达环保(600526 SH)重大资产重组方案再出变数。12月16日晚间,菲达环保公告,拟向杭钢集团发行股份购买其所持有的紫光环保62 9
-
闷声发大财!今年这些海外上游厂商股价远远跑赢特斯拉 近两年,电动车行业无疑是全球投资市场最引人注目的行业之一,尤其是电动车领军企业特斯拉的股价猛涨尤其令人惊叹。不过今年,由于上游...
-
和信投顾:沪指早盘小幅低开 芯片股持续低迷 【和信投顾:沪指早盘小幅低开芯片股持续低迷】截止午间收盘,沪指跌0 9%,深成指跌1 35%,创业板指跌1 38%。北向资金方面,沪股通早盘净流出3
-
爱好成就大奖 山东购彩者淡定领走足彩107万元 11月12日,烟台龙口传出喜报,在足彩胜平负14场第21136期中,龙口购彩者中得一等奖一注、二等奖九注,奖金合计1077044元。中奖后,大奖得主迟
-
 花呗影响个人负债率吗 影响借款人个人负债率的因素还有哪些? 如今互联网发展越来越快速,市面上的小额贷款也越来越多。支付宝平台有不少小贷产品,大家所熟知的蚂蚁花呗。日前,有一个朋友询问,花呗影
花呗影响个人负债率吗 影响借款人个人负债率的因素还有哪些? 如今互联网发展越来越快速,市面上的小额贷款也越来越多。支付宝平台有不少小贷产品,大家所熟知的蚂蚁花呗。日前,有一个朋友询问,花呗影 -
白酒股午后持续走低 来伊份触及跌停 每经AI快讯,白酒股午后持续走低,来伊份触及跌停,贵州茅台、老白干酒、泸州老窖、皇台酒业、五粮液等跌超3%。
-
稀土永磁板块持续走低 【稀土永磁板块持续走低】正海磁材、英洛华、银河磁体、大地熊、有研新材、宁波韵升跌超5%。
-
宝泰隆:目前未有石墨负极业务 【宝泰隆:目前未有石墨负极业务】宝泰隆(601011)在互动平台表示,目前公司拥有的石墨矿正在办理采矿权证,尚未进行开采。公司目前未有石墨负
-
硅宝科技:光伏太阳能用胶已全面进入太阳能光伏组件、BIPV等多个领域 【硅宝科技:光伏太阳能用胶已全面进入太阳能光伏组件、BIPV等多个领域】硅宝科技(300019)在接受机构调研时表示,公司光伏太阳能用胶已全面进
-
万集科技发布混合固态128线车规级激光雷达 【万集科技发布混合固态128线车规级激光雷达】记者获悉,12月16日,在广州召开的世界智能汽车大会上,万集科技发布了混合固态128线车规级激光
-
借鉴历史,哪些刺激消费政策值得期待? 据新华社报道,2021年12月6日中共中央政治局召开会议,分析研究当前经济形势和经济工作,指出“实施好扩大内需战略,促进消费持续恢复”...
-
 彝人老家:深度根植贫困县,辐射带动你我他 凉山州位于四川西南边陲,广袤无垠,层峦叠嶂,北起大渡河,南临金沙江山山水水在亘古岁月中见证着沧海桑田。山高谷深、林峰苍茫,是典型的深度
彝人老家:深度根植贫困县,辐射带动你我他 凉山州位于四川西南边陲,广袤无垠,层峦叠嶂,北起大渡河,南临金沙江山山水水在亘古岁月中见证着沧海桑田。山高谷深、林峰苍茫,是典型的深度 -
才高兴了一天!美股科技巨头全线下挫 终究仍躲不开美联储紧缩风暴? 【才高兴了一天!美股科技巨头全线下挫终究仍躲不开美联储紧缩风暴?】中国有句老话:“是福不是祸,是祸躲不过”,对于那些本周手中握...
-
IDC头部玩家光环新网定增落定,兴证财通诺德再上获配名单,海通广发银河同参与,ID... 12月16日,IDC头部玩家光环新网发布了规模30亿元的定增结果公告。光环新网是业界领先的互联网综合服务提供商,主营业务为互联网数据中心服务(I
-
巨丰投顾:整理不改向好趋势 A股跨年行情仍值得期待 【巨丰投顾:整理不改向好趋势A股跨年行情仍值得期待】观点:宏观面看,尽管短期经济回升,但整体经济增速放缓,下行压力依然较大。不过...
-
巨丰投顾:科技股回调致A股走弱 跨年行情迎低吸机会 【巨丰投顾:科技股回调致A股走弱跨年行情迎低吸机会】周五,A股低开低走,创业板领跌。盘面上,电源设备、电网设备、采掘、电力、房地...
-
源达:震荡仍是当下市场主基调 【源达:震荡仍是当下市场主基调】今日沪深两市指数整体呈现震荡调整格局。三大指数早盘均低开低走,弱势格局明显。
-
元旦当日车票 18日就能购买 天津北方网讯:从铁路部门获悉,进入12月中旬,根据最新铁路火车票预售期规定,2022年元旦火车票提前15天开售。明天可购买2022年元旦当天的火
-
水泥价格高价区触顶徘徊 煤价大降提升四季度毛利 临近年底,本应是各地工程赶进度,水泥价格最高的时候,而今年旺季不旺,水泥价格已连续下跌超一个月,较10月价格最高时有明显回落。而...
-
央行副行长陈雨露:继续完善准入前国民待遇和负面清单管理制度 【央行副行长陈雨露:继续完善准入前国民待遇和负面清单管理制度】中国人民银行副行长陈雨露在《中国金融》杂志最新撰文称,继续完善准...
-
山科智能项目入选2021年全国智慧企业建设创新案例 【山科智能项目入选2021年全国智慧企业建设创新案例】山科智能(300897)17日消息,公司与大连德泰水务有限公司合作开发的《基于智慧水务综合平
-
“新希望系”计划控股红星乳业 持股比例或在51%—60% 【“新希望系”计划控股红星乳业持股比例或在51%—60%】近日,新希望乳业董事长席刚出任红星乳业董事职位,另有“新希望系”高管邱屿、...
-
巨丰投顾:整理不改向好趋势 A股跨年行情仍值得期待 【巨丰投顾:整理不改向好趋势A股跨年行情仍值得期待】观点:宏观面看,尽管短期经济回升,但整体经济增速放缓,下行压力依然较大。不过...
热门资讯
- 前三季度完成交通固定资产投资25632亿元 同比增长2% 记者今天从交通运输部获悉,前三季...
- 1-9月份第一产业投资10395亿元 同比增长14.0% 据国家统计局官网消息,1-9月份,...
- 1-8月河南省货物贸易保持高速增长 商务运行稳中有进 据河南省商务厅官网消息,2021年1-...
- 医药板块投资性价比显现 基金公司密集调研医药上市公司 12月14日,资本邦了解到,随着年内...
文章排行
图赏
-
 拓荆科技针对科创板第二轮问询相关问题进行问询回复 盈利能力不足、产品类型单一且周转...
拓荆科技针对科创板第二轮问询相关问题进行问询回复 盈利能力不足、产品类型单一且周转... -
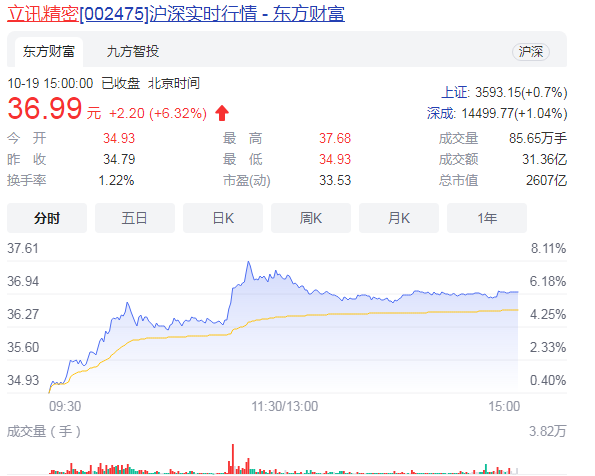 立讯精密涨6.32%目前报价36.99元 这家企业主要是干什么的? 据最新消息显示,立讯精密涨6 32%...
立讯精密涨6.32%目前报价36.99元 这家企业主要是干什么的? 据最新消息显示,立讯精密涨6 32%... -
 国漫多利好迈入黄金期 头部动漫公司扎堆IPO 今年以来,动漫市场绽放异彩。暑期...
国漫多利好迈入黄金期 头部动漫公司扎堆IPO 今年以来,动漫市场绽放异彩。暑期... -
 4月1日起 北京市燃油车不得占用充电专用泊位 充电站必须配专人巡检 今日,记者从北京市市场监管局网站...
4月1日起 北京市燃油车不得占用充电专用泊位 充电站必须配专人巡检 今日,记者从北京市市场监管局网站...